
Nithin Puthenveettil
Sunday, March 8, 2026
Training a Local LLM (Qwen3.5-2B) to Generate Git Commit Messages Using MLX + LoRA
I trained a small local LLM to generate conventional Git commit messages directly from diffs.The entire setup runs locally on a MacBook using MLX + LoRA, and training took about 25 minutes.Here is how the pipeline works.
TL;DR
- Fine-tuned Qwen3.5-2B-Base locally using MLX + LoRA
- Built a dataset of ~1400 commit diffs
- Training took ~25 minutes on a MacBook M4 Pro
- Final model generates conventional commit messages from diffs
- Git Repo: https://github.com/nithinputhenveettil/mlx-llm-commit-message-finetuning
Example:
Diff:
+ add JWT validation
+ reject expired tokens
Output:
feat(core): add JWT validation and reject expired tokens
Introduction
Machine Learning has fascinated me for a very long time.
Back in 2014, while working on my college academic project, I remember reading research papers and being completely amazed by the idea that instead of writing endless if-else rules, we could train a model and let it learn the logic itself.
The funny part is, my setup back then was terrible.
I had:
- A Linux PC
- Intel dual-core CPU
- 2GB RAM
- An Idea 2G data card
Internet speed was painfully slow and unstable. Sometimes it felt worse than dial-up.
To train my model I literally had to kill the X server (Linux GUI) so that the CPU and RAM could focus only on training.
That college project was an authorship prediction model which tried to identify which author wrote a given book. The code is still on GitHub if anyone is curious:
https://github.com/nithinputhenveettil/authorship-predictor
Fast forward 12 years, and yesterday I decided to train another model.
This time the goal was simple:
Train a small local LLM to generate conventional Git commit messages directly from diffs.
Thankfully computing power is not a problem anymore. My current machine is a MacBook Pro with M4 Pro and 24GB RAM.
The hardware has changed. The tools have changed.
But the excitement of training a model? Exactly the same.
So in this post I will walk through how I built a commit message generator that runs completely locally on my laptop.
The Setup
Here is the exact setup I used:
- MacBook Pro (M4 Pro, 24GB RAM)
- Python
- MLX
- LoRA (Low Rank Adaptation)
- Model:
Qwen3.5-2B-Base - LM Studio (for testing)
The idea was to fine-tune this 2B parameter model so that it can look at a git diff and generate a proper commit message.
Mostly because I am lazy and I don’t want to type them myself.
The Trouble with Commit Messages
Writing good commit messages is a small but constant friction in daily development.
Most of us end up writing things like:
fix stuff
update code
minor change
But well-structured commit messages are actually very useful. They improve:
- Code history readability
- Automated changelogs
- Release notes
- Collaboration across teams
The Conventional Commits format solves this nicely:
feat(auth): add JWT validation
fix(api): handle invalid token error
refactor(core): simplify request pipeline
However writing them manually every time still feels repetitive.
So I wondered:
Can I train a small local LLM to generate conventional commit messages directly from git diffs?
That is exactly what this experiment tries to do.
Overview
The pipeline looks like this.

Git repositories
↓
Extract commits and diffs
↓
Clean and balance dataset
↓
Fine tune model with LoRA
↓
Generate commit messages
The model basically learns this mapping:
git diff → conventional commit message
Choosing the Model
For this experiment I used:
Qwen3.5-2B-Base
Reasons:
- Small enough to run locally
- Good instruction capability
- Works nicely with MLX
To train locally on Apple Silicon I used MLX, Apple’s machine learning framework optimized for Apple GPUs.
For fine-tuning I used LoRA (Low Rank Adaptation).
Instead of updating the entire model, LoRA only trains a very small subset of parameters.
Example training output:
Trainable parameters: 0.298% (5.6M / 1.88B)
So we are training less than 1% of the model.
Building the Dataset
To train the model we need examples of:
Diff → Commit message
I collected commits from several popular repositories that mostly follow conventional commit style. (and yes, tools like ChatGPT helped generate some of the boilerplate scripts for extracting the dataset)
Repositories used:
angular
cz-cli
nest
next.js
semantic-release
From each repository I extracted:
- commit message
- git diff
Example training pair:
Diff:
+ add JWT validation
+ reject expired tokens
Commit:
feat(auth): add JWT validation and reject expired tokens
Cleaning the Dataset
Raw commit history contains a lot of noise:
- merge commits
- very large diffs
- bot commits
- inconsistent formatting
So several filters were applied.
Remove large diffs
Large diffs do not fit the model context window.
if diff.count("\n") > 200:
skip
Enforce conventional commit format
Only these commit types were kept:
feat
fix
refactor
perf
Balance commit types
If one type dominates, the model becomes biased.
Final dataset distribution:
refactor 400
feat 400
fix 400
perf 200
Total dataset size:
~1400 samples
The Dataset Extraction Script
In case you want to replicate this setup yourself, here is the exact Python script I used to scrape, filter, and build the dataset directly from local git repositories. It handles all the heavy lifting: extracting diffs, ditching garbage commits, and ensuring our final sample sizes are perfectly balanced.
Just clone whatever repositories you want to use into a repos directory and run this script. It will magically create a dataset folder for you.
import subprocess
import json
import random
import re
from pathlib import Path
from collections import defaultdict
# Config
REPOS_DIR = "repos"
OUTPUT_DIR = "dataset"
MAX_DIFF_CHARS = 2000
MAX_DIFF_LINES = 200
MIN_DIFF_LINES = 3
VALID_SPLIT = 0.1
TARGET_PER_TYPE = {
"feat": 400,
"fix": 400,
"refactor": 400,
"perf": 200
}
TYPE_REGEX = re.compile(r"^(feat|fix|refactor|perf)(\(.+\))?:", re.IGNORECASE)
# GIT HELPERS
def get_commits(repo_path):
commits = subprocess.check_output(
["git", "-C", repo_path, "log", "--pretty=%H|%s"],
text=True
).splitlines()
for line in commits:
try:
sha, msg = line.split("|", 1)
except ValueError:
continue
yield sha, msg.strip()
def get_diff(repo_path, sha):
try:
diff = subprocess.check_output(
["git", "-C", repo_path, "show", sha, "--pretty=", "--unified=0"],
text=True,
stderr=subprocess.DEVNULL
)
except:
return None
if not diff:
return None
# skip very large diffs
if diff.count("\n") > MAX_DIFF_LINES:
return None
if len(diff) > MAX_DIFF_CHARS:
diff = diff[:MAX_DIFF_CHARS]
# keep only actual code changes
diff_lines = [
line for line in diff.splitlines()
if (line.startswith("+") or line.startswith("-"))
and not line.startswith("+++")
and not line.startswith("---")
]
if len(diff_lines) < MIN_DIFF_LINES:
return None
diff = "\n".join(diff_lines)
return diff
# CLEANERS
def clean_message(msg):
msg = msg.replace("<|im_end|>", "")
msg = msg.strip()
return msg
# DATASET FORMATTER
def build_example(diff, message):
return {
"messages": [
{
"role": "user",
"content": f"Generate a conventional commit message for this diff:\n\n{diff}"
},
{
"role": "assistant",
"content": message
}
]
}
# MAIN DATASET BUILDER
def main():
Path(OUTPUT_DIR).mkdir(exist_ok=True)
buckets = defaultdict(list)
for repo in Path(REPOS_DIR).iterdir():
if not repo.is_dir():
continue
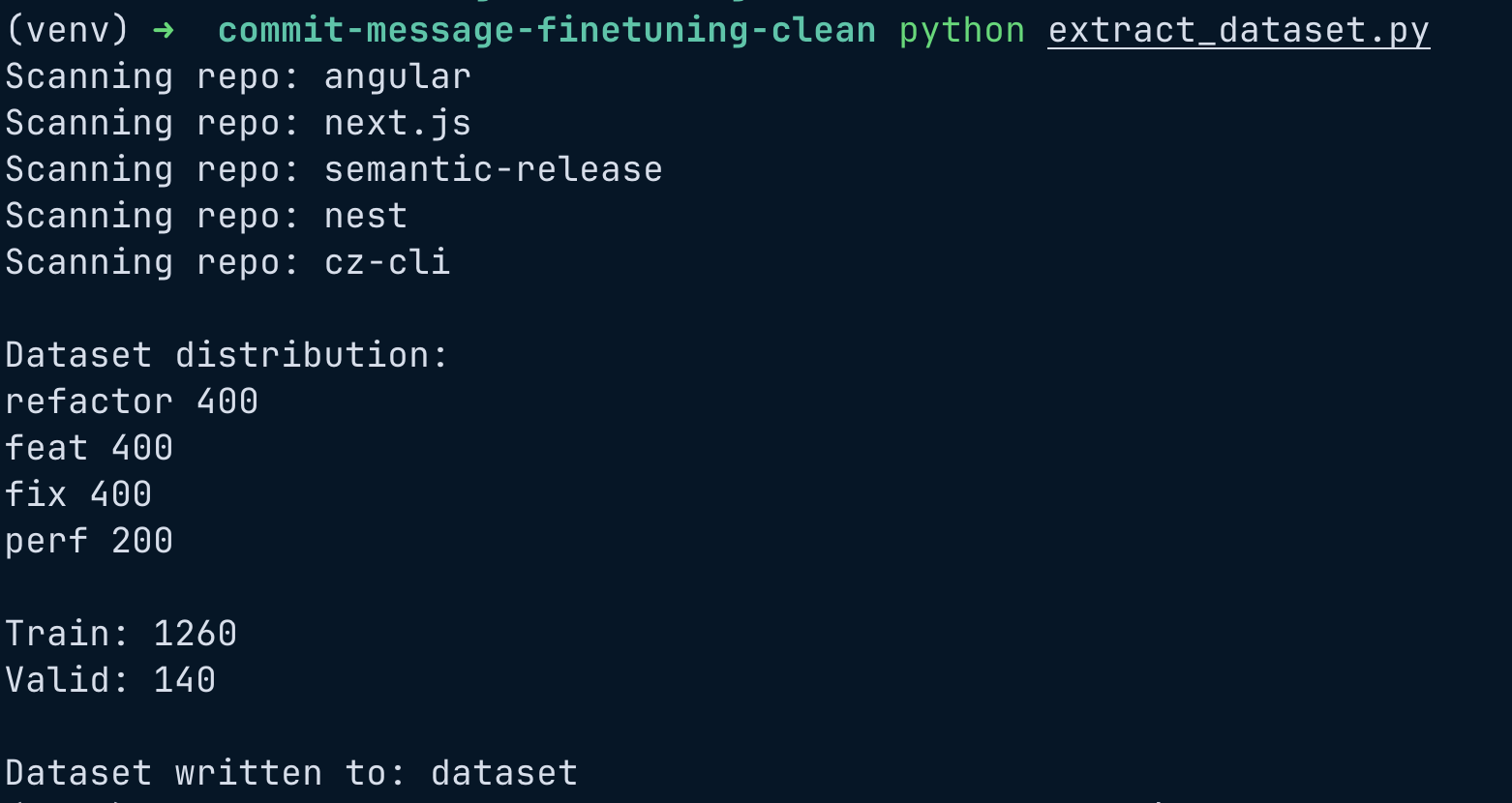
print("Scanning repo:", repo.name)
for sha, msg in get_commits(str(repo)):
msg = clean_message(msg)
match = TYPE_REGEX.match(msg)
if not match:
continue
commit_type = match.group(1).lower()
if commit_type not in TARGET_PER_TYPE:
continue
if len(buckets[commit_type]) >= TARGET_PER_TYPE[commit_type]:
continue
diff = get_diff(str(repo), sha)
if not diff:
continue
example = build_example(diff, msg)
buckets[commit_type].append(example)
# combine dataset
dataset = []
for k, v in buckets.items():
dataset.extend(v)
random.shuffle(dataset)
# split train / valid
split_index = int(len(dataset) * (1 - VALID_SPLIT))
train = dataset[:split_index]
valid = dataset[split_index:]
# write train set
with open(f"{OUTPUT_DIR}/train.jsonl", "w") as f:
for row in train:
f.write(json.dumps(row) + "\n")
# write validation set
with open(f"{OUTPUT_DIR}/valid.jsonl", "w") as f:
for row in valid:
f.write(json.dumps(row) + "\n")
# stats
print("\nDataset distribution:")
for k, v in buckets.items():
print(k, len(v))
print("\nTrain:", len(train))
print("Valid:", len(valid))
print("\nDataset written to:", OUTPUT_DIR)
if __name__ == "__main__":
main()
Training the Model
Training was done using MLX LoRA.
mlx_lm.lora \
--model ./Qwen3.5-2B-Base \
--train \
--data ./dataset \
--batch-size 1 \
--iters 1000 \
--learning-rate 5e-5 \
--max-seq-length 256 \
--adapter-path commit-lora-new
A few important parameters to note:
| Parameter | Value |
|---|---|
| Iterations | 1000 |
| Batch size | 1 |
| Sequence length | 256 |
| Learning rate | 5e-5 |
Note: Please be informed that I had to do quite a bit of trial-and-error with these parameters to actually get decent results.
Training ran on the Apple GPU via MLX.
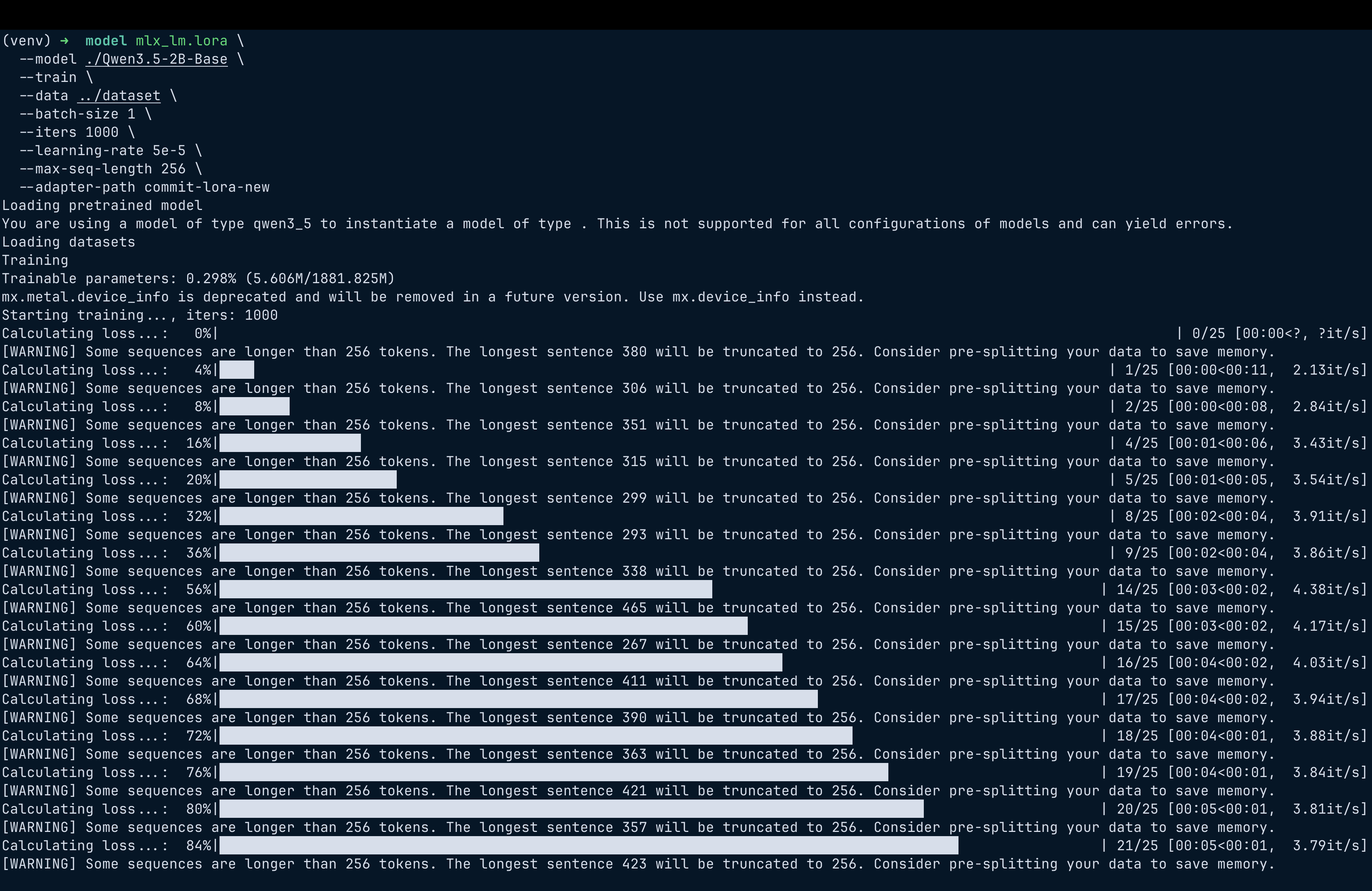
Training time was around 20–25 minutes.
Training Progress
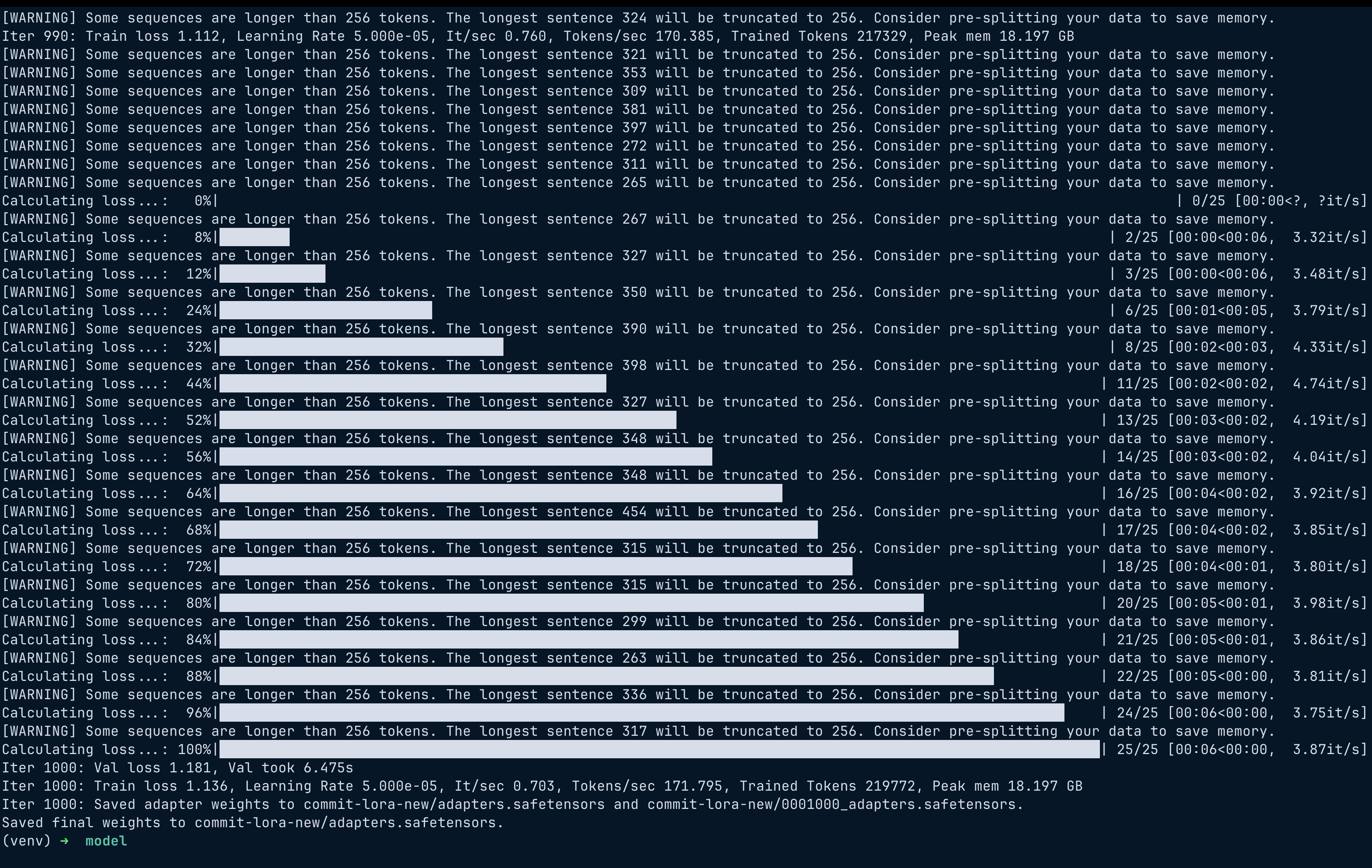
Logs showed steady improvement.
Iter 1: Val loss 1.66
Iter 200: Val loss 1.30
Iter 400: Val loss 1.25
Iter 1000: Val loss 1.18
Final result:
Train loss: 1.13
Val loss: 1.18
Adapter Files
After training MLX generated LoRA adapter weights.
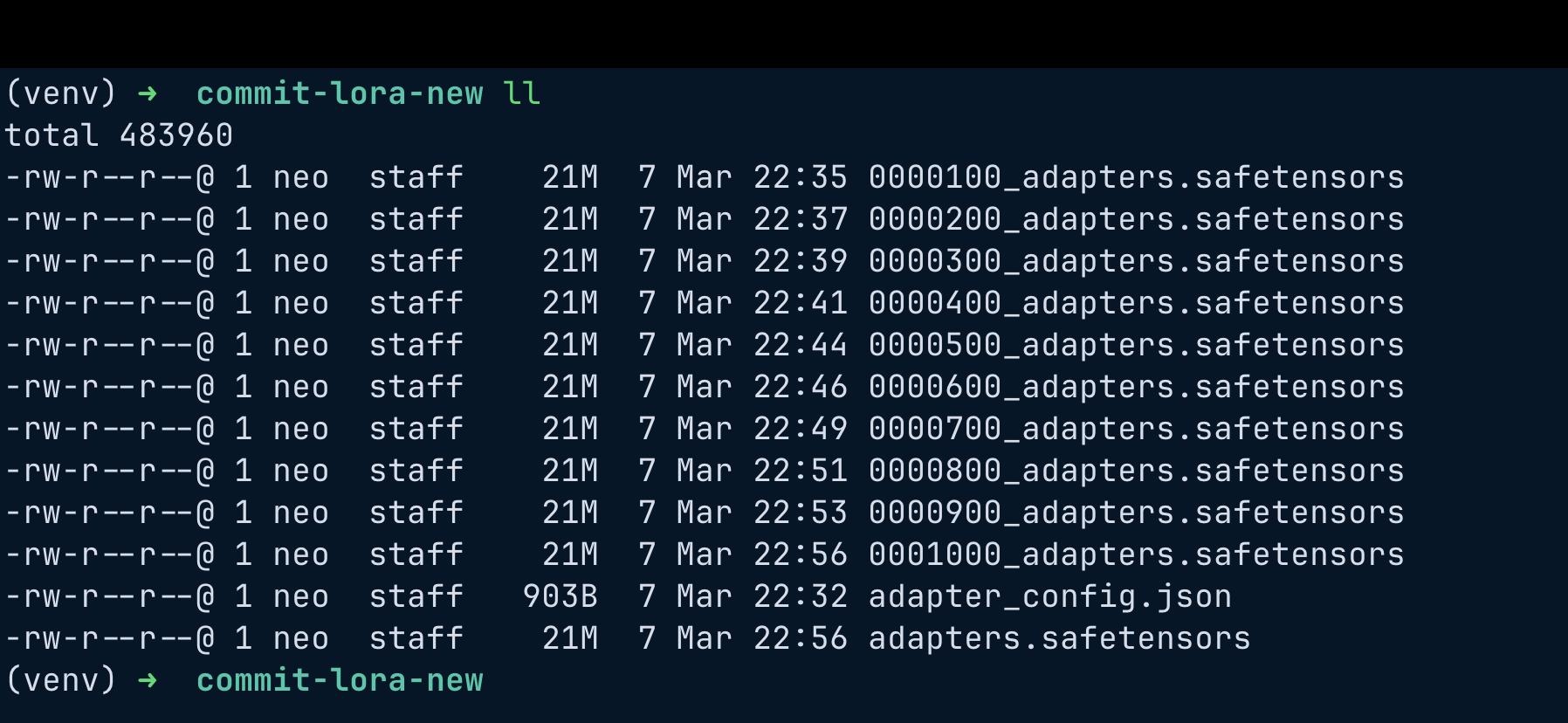
These adapters are only around 20MB, which is much smaller than the base model.
Testing the Model
Example prompt:
Generate a conventional commit message.
Diff:
+ add JWT validation
+ reject expired tokens
Commit:
Inference command:
mlx_lm.generate \
--model ./Qwen3.5-2B-Base \
--adapter-path ./commit-lora-new \
--temp 0 \
--max-tokens 20 \
--prompt "<prompt>"
Results
Let’s compare the base model vs fine-tuned model.
Base Model
add JWT validation
reject expired tokens
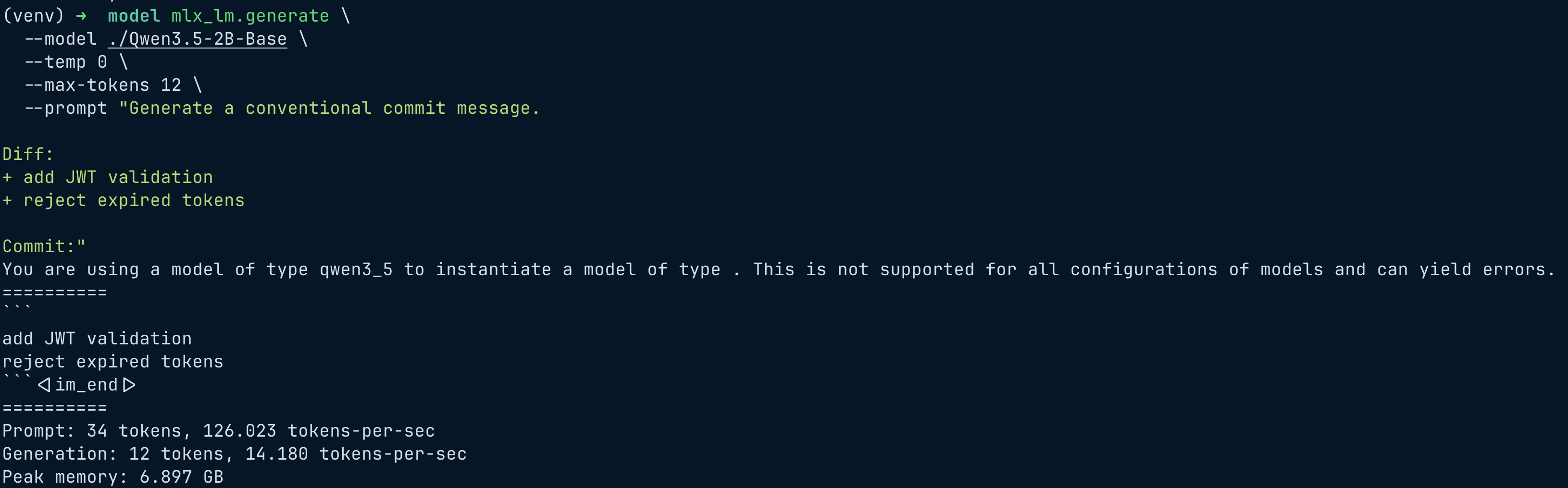
The base model simply repeats the diff.
Fine-Tuned Model
feat(core): add JWT validation and reject expired tokens(#63444)
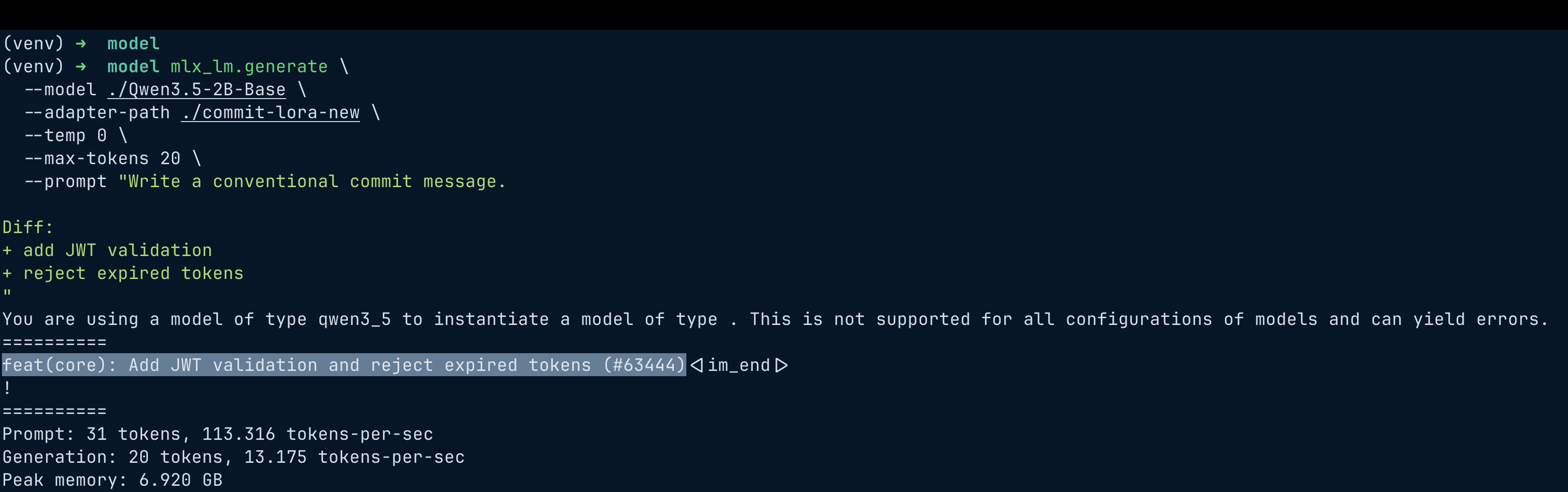
The fine-tuned model:
- follows conventional commit format
- summarizes the change
- sometimes generates scopes
Occasionally it even adds fake PR numbers like:
feat(core): add JWT validation (#12345)
The model hallucinated the PR number because most of the commit messages in our training set actually had PR numbers glued to them. But honestly, that’s not a big deal. For my use case, all I wanted was for the model to learn the conventional commit structure, and this proves that it absolutely did. In a way, even this hallucination is a strong sign of success!
Limitations
This experiment is relatively small.
Small dataset
Only about:
1400 commits
Production systems usually train on tens of thousands.
Diff truncation
Diffs longer than 256 tokens are truncated.
Occasional hallucinations
Sometimes the model generates extra information like PR numbers.
Future Improvements
Possible improvements:
Larger dataset
Repositories like:
react
kubernetes
docker
terraform
would improve training quality.
Better scope detection
Scopes could be inferred from directories like:
auth/
api/
core/
Longer context window
Increasing sequence length to 384–512 tokens.
Why Local Fine Tuning is Interesting
The most satisfying part of this experiment is that everything runs locally.
No cloud GPUs.
No expensive infrastructure.
Just:
MacBook + MLX + LoRA
Local fine-tuning makes it easy for developers to experiment with domain-specific models.
Final Thoughts
Even with a relatively small dataset and lightweight fine-tuning, the model learned to:
- interpret git diffs
- generate conventional commit messages
- follow commit style patterns
And the entire pipeline runs comfortably on a laptop.
As local LLM tooling improves, we will likely see more specialised developer assistants for tasks like:
- commit generation
- PR summaries
- code review suggestions
- changelog generation
Small focused models like this can actually be very powerful.
Try It Yourself
If you want to experiment with this yourself, the steps are roughly:
- Collect commits and diffs from a few repositories.
- Clean and balance the dataset.
- Train a LoRA adapter using MLX.
- Run inference using the base model + adapter.
You can find the full scripts, dataset preparation steps, and training instructions in the repository: https://github.com/nithinputhenveettil/mlx-llm-commit-message-finetuning
Example inference command:
mlx_lm.generate \
--model ./Qwen3.5-2B-Base \
--adapter-path ./commit-lora \
--temp 0 \
--max-tokens 20 \
--prompt "Generate a conventional commit message.
Diff:
+ add JWT validation
+ reject expired tokens
"
References
MLX
https://github.com/ml-explore/mlx
Conventional Commits
https://www.conventionalcommits.org/